# Artificial Text Detection
This project is based on my Master's thesis:
> **"Алгоритм выявления искусственно созданных текстов"**
> Nizhny Novgorod State Technical University, 2021
> Author: Andrey Kuznetsov
It is a C++/Qt-based application designed to detect artificially generated
scientific texts (e.g., SCIgen outputs). The detection method is based on
analyzing the internal stylistic consistency of the document using unsupervised
clustering and rank correlation metrics.
 ## Project Overview
The program processes input text, splits it into fragments, builds a vector
space using N-gram features, computes a pairwise distance matrix using
Spearman rank correlation, and applies clustering to detect stylistic
discontinuities. Such discontinuities are often present in machine-generated
texts.
## Technologies Used
- **C++17 (STL)**
- **Qt 5 Widgets & Charts**
- **Boost**:
- `boost::python` and `boost::python::numpy` — Used to exchange Numpy arrays
between C++ and Python during clustering.
- **Python 3** (invoked from C++):
- `numpy`
- `scikit-learn`
- `scikit-learn-extra`
## Features
### Flexible Text Input
- Manual text input via the built-in editor
- File selection via file dialog
- **Drag and drop** support for `.txt` files
### Text Preprocessing
- Removes stop words, non-letter symbols, and repeated spaces
- Converts text to lowercase
- Implemented in a dedicated `prepare()` function for consistent cleaning
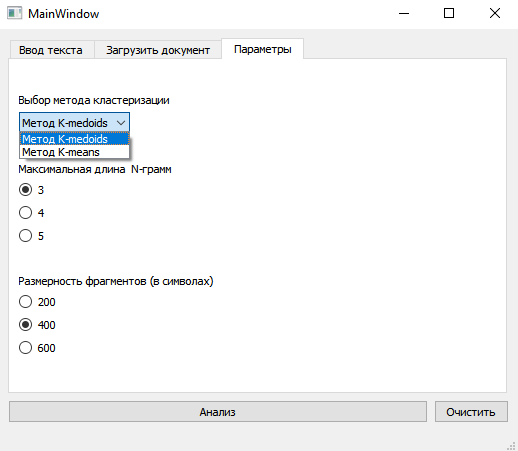
### N-Gram Extraction and Dictionary Building
- Extracts N-grams with:
- Minimum N = 2
- Maximum N set via UI parameters
- Builds a global dictionary from all fragments
- Performs feature selection by filtering top N-grams based on 90% frequency threshold
### Vector Space Model Construction
- Uses the selected dictionary to vectorize document fragments
- Produces a nested structure: `vector>>`
where:
- Outer vector = documents
- Middle vector = fragments
- Inner vector = N-gram frequencies
### Distance Calculation Using Rank Correlation
- Calculates pairwise distances between fragments using **Spearman’s rank correlation coefficient**
- Computes **average rank dependence (ZVT)** with a sliding window approach
- Handles inter-document and intra-document fragment comparisons
### Matrix Normalization
- Normalizes the pairwise distance matrix shape by padding shorter rows with zeros
- Ensures consistent dimensions for clustering algorithms
### Unsupervised Clustering with Python
- Clustering algorithms supported:
- **K-Medoids**
- **K-Means**
- **Agglomerative Clustering**
- Implemented in Python using:
- `scikit-learn`
- `scikit-learn-extra`
- Distance matrix passed from C++ to Python via:
- `Boost.Python`
- `Boost.NumPy`
### C++ Python Interoperability
To perform clustering with Python libraries, the project uses `Boost.Python` and `Boost.NumPy`:
- Converts a `std::vector>` (distance matrix) to a NumPy array.
- Initializes the embedded Python interpreter.
- Imports the custom Python module `mymodule.py`.
- Calls one of the clustering functions: `kmedoids`, `kmeans`, or `agglClus`.
- Extracts prediction results and returns them back to C++.
This approach allows combining the performance and UI capabilities of C++/Qt with the ML power of Python.
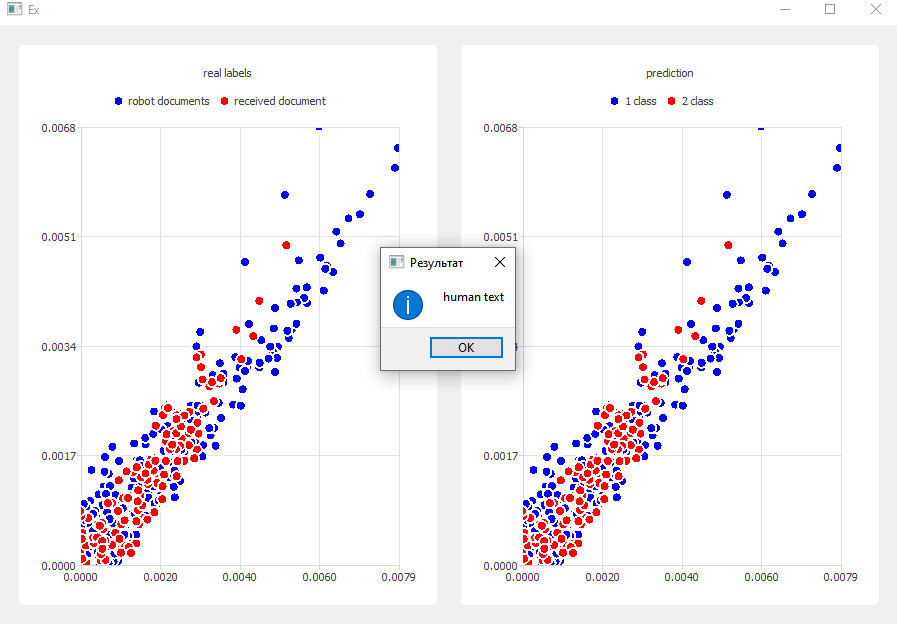
### Visualization
- Displays predicted vs. real document labels in two separate charts.
- Cluster assignments are color-coded.
- Charts are rendered interactively via Qt.
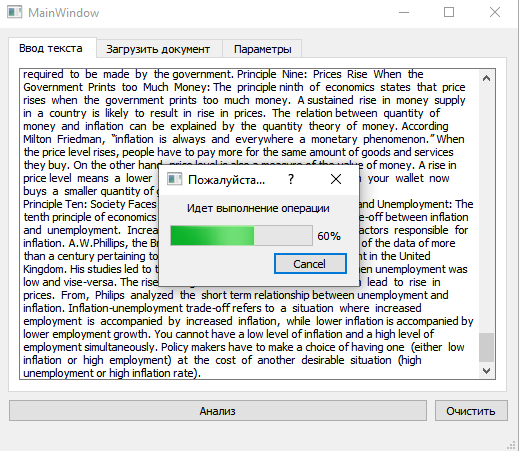
### Multithreaded Execution with Progress Bar
- Runs the detection algorithm in a separate thread using `QThread`
- Keeps the GUI responsive during processing
- Displays progress via `QProgressDialog`
## Algorithm Pipeline (Detailed)
1. **Text Input**
- User provides text via input box, file dialog, or drag-and-drop.
- Text is stored in `target_doc`.
2. **Preprocessing** (`prepare()`)
- Removes stop words (prepositions, conjunctions, etc.)
- Removes all characters except letters and spaces
- Removes repeated characters (e.g., spaces)
- Converts text to lowercase
3. **Fragmentation**
- Text is split into equal-length chunks based on UI parameters
4. **N-Gram Extraction**
- Combines all documents into a single corpus
- Calculates N-grams for N from 2 up to max N (from UI)
- Uses a sliding window algorithm
- Aggregates results into a dictionary
5. **N-Gram Filtering**
- Selects N-grams above 90th percentile of frequency
- Saves filtered list to a text file
6. **Vector Space Modeling**
- For each document, for each fragment:
- Computes vector of N-gram frequencies via `freq_in_chunk()`
- Produces nested structure of frequency vectors
7. **Rank Correlation (Spearman's rho)**
- Calculates rank correlation distance between fragment vectors:
ρ = 1 - (6 * ∑ d_i^2) / (n(n^2 - 1))
- Implemented via `zv_calc()` and `correlation()`
8. **Average Rank Dependence**
- Computes `ZVT` values for each fragment (based on 10 previous)
- Combines `ZVT` into full pairwise distance matrix
9. **Matrix Padding**
- Matrix may have uneven rows; padded with zeros to square shape
10. **C++ to Python Transfer**
- Converts distance matrix to NumPy arrays using `Boost.NumPy`
- Initializes embedded Python interpreter
- Calls `mymodule.py::{kmedoids, kmeans, agglClus}`
- Extracts prediction results
11. **Post-Processing Results**
- Splits results into clusters for artificial vs. input document
- Compares distributions:
- If both match → **Artificial text**
- If different → **Human-written text**
12. **Visualization & UI**
- Result shown in message box
- Prediction charts drawn with `QChartView`
## Build Instructions
### Prerequisites
Before building, make sure the following are installed:
- **Qt 5.x** (QtWidgets, QtCharts, QtCore, QtGui)
- **Boost** (with `Boost.Python` and `Boost.NumPy` modules built)
- **Python 3.x** (tested with Python 3.8)
- Python packages:
```bash
pip install numpy scikit-learn scikit-learn-extra
```
### Boost Notes
- You must build Boost with Python support (`b2 --with-python`).
- Ensure that Boost is compiled with the same Python version you plan to use.
- On Windows, you may need to specify Boost and Python library paths in the `.pro` file, for example:
```qmake
LIBS += \
-L"C:\Program Files\boost\boost_1_76_0\stage\x86\lib" \
-LC:/Users//AppData/Local/Programs/Python/Python38-32/libs
```
### Building
- Clone the repository:
```
git clone https://git.scratko.xyz/artifical-text-detection
cd artifical-text-detection
```
- Open the `.pro` file in Qt Creator.
- Adjust library paths for Boost and Python if necessary.
- Build and run the project.
### Running
- Ensure that the Python interpreter can import mymodule.py.
- Make sure required Python packages are installed in the environment used by the application.
## Notes
- Designed to detect machine-generated documents, especially SCIgen-based fakes.
- Easily extendable to detect LLM-generated texts with modified features.
- No pretrained models required — fully unsupervised method.
## Project Overview
The program processes input text, splits it into fragments, builds a vector
space using N-gram features, computes a pairwise distance matrix using
Spearman rank correlation, and applies clustering to detect stylistic
discontinuities. Such discontinuities are often present in machine-generated
texts.
## Technologies Used
- **C++17 (STL)**
- **Qt 5 Widgets & Charts**
- **Boost**:
- `boost::python` and `boost::python::numpy` — Used to exchange Numpy arrays
between C++ and Python during clustering.
- **Python 3** (invoked from C++):
- `numpy`
- `scikit-learn`
- `scikit-learn-extra`
## Features
### Flexible Text Input
- Manual text input via the built-in editor
- File selection via file dialog
- **Drag and drop** support for `.txt` files
### Text Preprocessing
- Removes stop words, non-letter symbols, and repeated spaces
- Converts text to lowercase
- Implemented in a dedicated `prepare()` function for consistent cleaning
### N-Gram Extraction and Dictionary Building
- Extracts N-grams with:
- Minimum N = 2
- Maximum N set via UI parameters
- Builds a global dictionary from all fragments
- Performs feature selection by filtering top N-grams based on 90% frequency threshold
### Vector Space Model Construction
- Uses the selected dictionary to vectorize document fragments
- Produces a nested structure: `vector>>`
where:
- Outer vector = documents
- Middle vector = fragments
- Inner vector = N-gram frequencies
### Distance Calculation Using Rank Correlation
- Calculates pairwise distances between fragments using **Spearman’s rank correlation coefficient**
- Computes **average rank dependence (ZVT)** with a sliding window approach
- Handles inter-document and intra-document fragment comparisons
### Matrix Normalization
- Normalizes the pairwise distance matrix shape by padding shorter rows with zeros
- Ensures consistent dimensions for clustering algorithms
### Unsupervised Clustering with Python
- Clustering algorithms supported:
- **K-Medoids**
- **K-Means**
- **Agglomerative Clustering**
- Implemented in Python using:
- `scikit-learn`
- `scikit-learn-extra`
- Distance matrix passed from C++ to Python via:
- `Boost.Python`
- `Boost.NumPy`
### C++ Python Interoperability
To perform clustering with Python libraries, the project uses `Boost.Python` and `Boost.NumPy`:
- Converts a `std::vector>` (distance matrix) to a NumPy array.
- Initializes the embedded Python interpreter.
- Imports the custom Python module `mymodule.py`.
- Calls one of the clustering functions: `kmedoids`, `kmeans`, or `agglClus`.
- Extracts prediction results and returns them back to C++.
This approach allows combining the performance and UI capabilities of C++/Qt with the ML power of Python.
### Visualization
- Displays predicted vs. real document labels in two separate charts.
- Cluster assignments are color-coded.
- Charts are rendered interactively via Qt.
### Multithreaded Execution with Progress Bar
- Runs the detection algorithm in a separate thread using `QThread`
- Keeps the GUI responsive during processing
- Displays progress via `QProgressDialog`
## Algorithm Pipeline (Detailed)
1. **Text Input**
- User provides text via input box, file dialog, or drag-and-drop.
- Text is stored in `target_doc`.
2. **Preprocessing** (`prepare()`)
- Removes stop words (prepositions, conjunctions, etc.)
- Removes all characters except letters and spaces
- Removes repeated characters (e.g., spaces)
- Converts text to lowercase
3. **Fragmentation**
- Text is split into equal-length chunks based on UI parameters
4. **N-Gram Extraction**
- Combines all documents into a single corpus
- Calculates N-grams for N from 2 up to max N (from UI)
- Uses a sliding window algorithm
- Aggregates results into a dictionary
5. **N-Gram Filtering**
- Selects N-grams above 90th percentile of frequency
- Saves filtered list to a text file
6. **Vector Space Modeling**
- For each document, for each fragment:
- Computes vector of N-gram frequencies via `freq_in_chunk()`
- Produces nested structure of frequency vectors
7. **Rank Correlation (Spearman's rho)**
- Calculates rank correlation distance between fragment vectors:
ρ = 1 - (6 * ∑ d_i^2) / (n(n^2 - 1))
- Implemented via `zv_calc()` and `correlation()`
8. **Average Rank Dependence**
- Computes `ZVT` values for each fragment (based on 10 previous)
- Combines `ZVT` into full pairwise distance matrix
9. **Matrix Padding**
- Matrix may have uneven rows; padded with zeros to square shape
10. **C++ to Python Transfer**
- Converts distance matrix to NumPy arrays using `Boost.NumPy`
- Initializes embedded Python interpreter
- Calls `mymodule.py::{kmedoids, kmeans, agglClus}`
- Extracts prediction results
11. **Post-Processing Results**
- Splits results into clusters for artificial vs. input document
- Compares distributions:
- If both match → **Artificial text**
- If different → **Human-written text**
12. **Visualization & UI**
- Result shown in message box
- Prediction charts drawn with `QChartView`
## Build Instructions
### Prerequisites
Before building, make sure the following are installed:
- **Qt 5.x** (QtWidgets, QtCharts, QtCore, QtGui)
- **Boost** (with `Boost.Python` and `Boost.NumPy` modules built)
- **Python 3.x** (tested with Python 3.8)
- Python packages:
```bash
pip install numpy scikit-learn scikit-learn-extra
```
### Boost Notes
- You must build Boost with Python support (`b2 --with-python`).
- Ensure that Boost is compiled with the same Python version you plan to use.
- On Windows, you may need to specify Boost and Python library paths in the `.pro` file, for example:
```qmake
LIBS += \
-L"C:\Program Files\boost\boost_1_76_0\stage\x86\lib" \
-LC:/Users//AppData/Local/Programs/Python/Python38-32/libs
```
### Building
- Clone the repository:
```
git clone https://git.scratko.xyz/artifical-text-detection
cd artifical-text-detection
```
- Open the `.pro` file in Qt Creator.
- Adjust library paths for Boost and Python if necessary.
- Build and run the project.
### Running
- Ensure that the Python interpreter can import mymodule.py.
- Make sure required Python packages are installed in the environment used by the application.
## Notes
- Designed to detect machine-generated documents, especially SCIgen-based fakes.
- Easily extendable to detect LLM-generated texts with modified features.
- No pretrained models required — fully unsupervised method.